|
|
一、安装Hadoop 1.先解压hadoop到相关的文件夹中 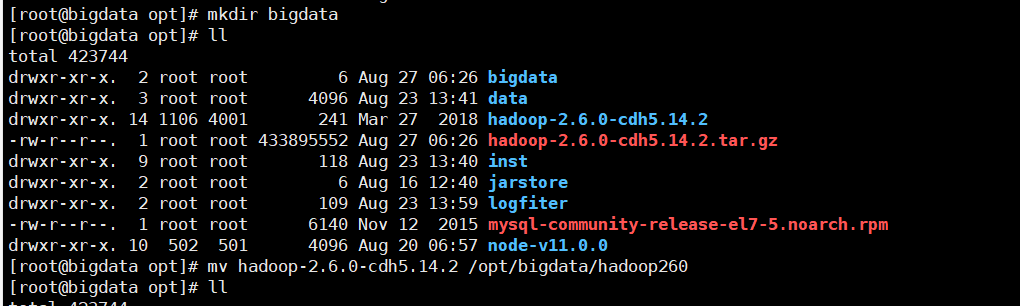
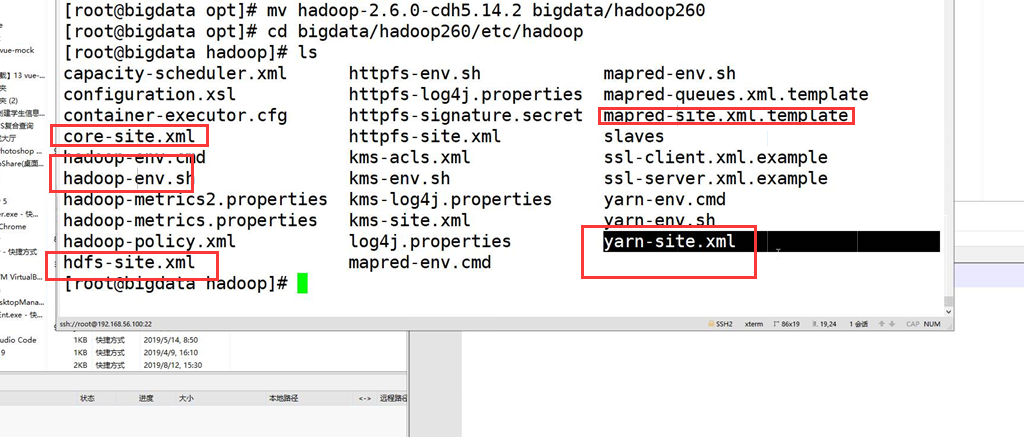
2.进入到解压好的文件夹以后,对相关文件进行修改 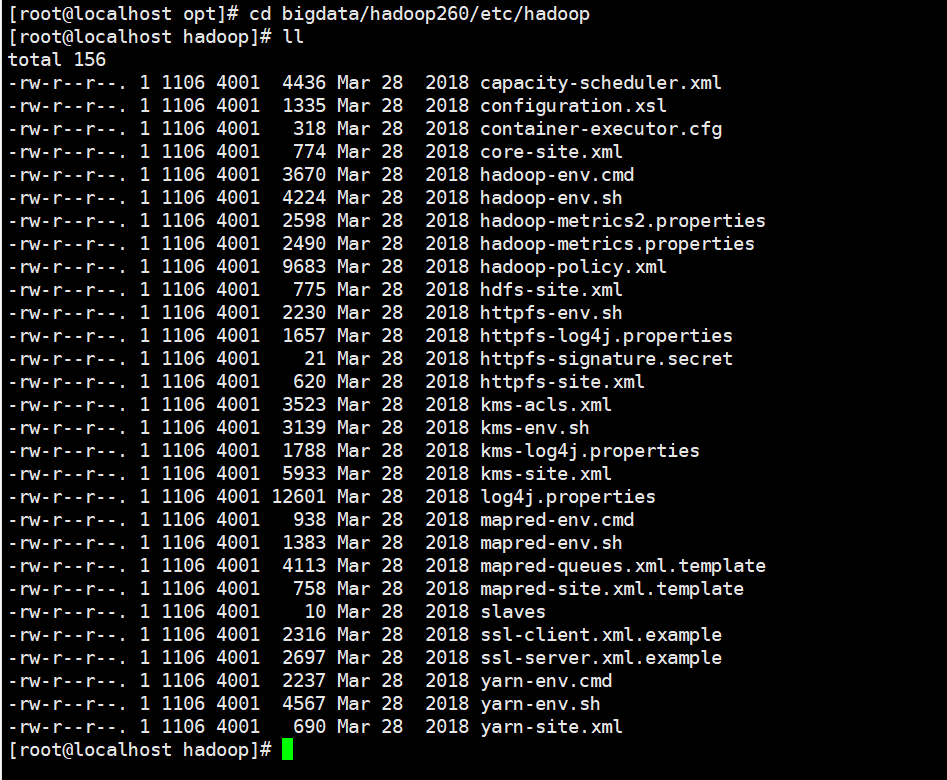
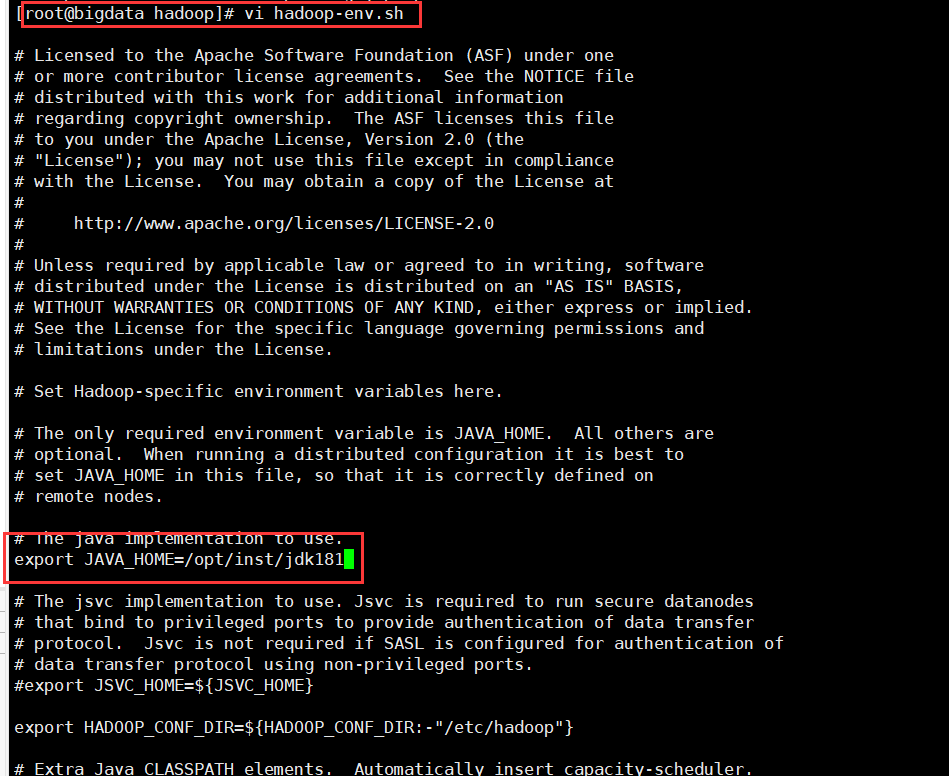
3.配置hadoop-env.sh vi hadoop-env.sh:
export= JAVA_HOME=/opt/inst/jdk181 |
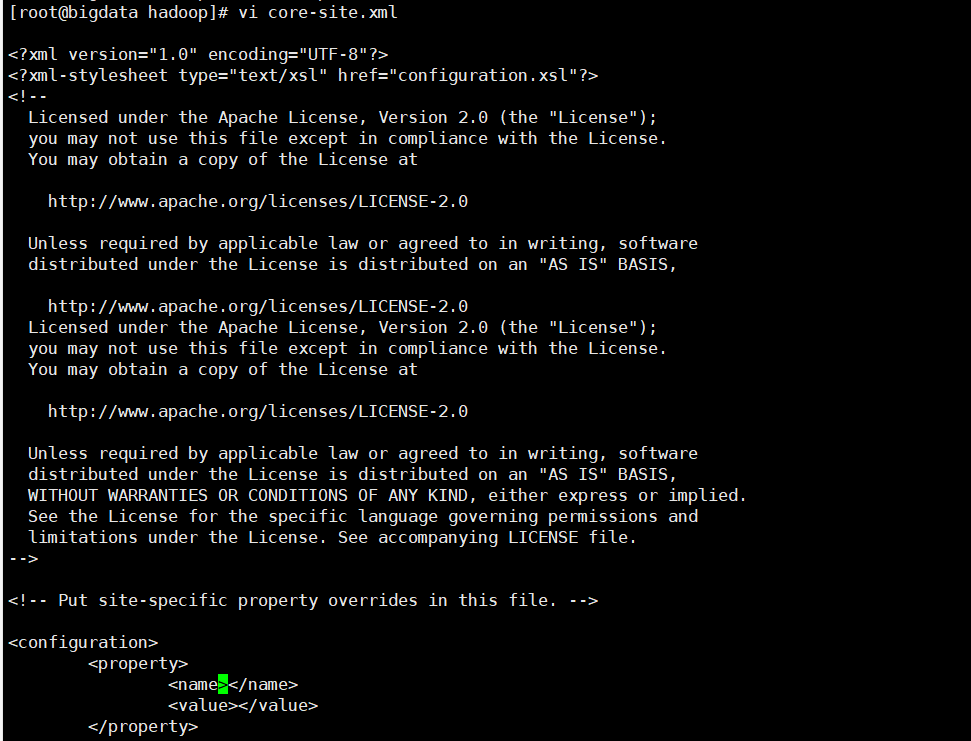
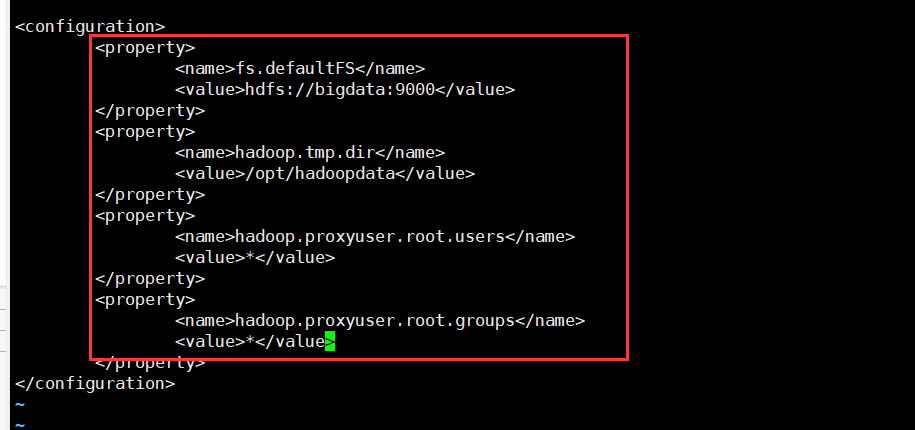
4.配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopdata</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property> |
5.配置hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property> |

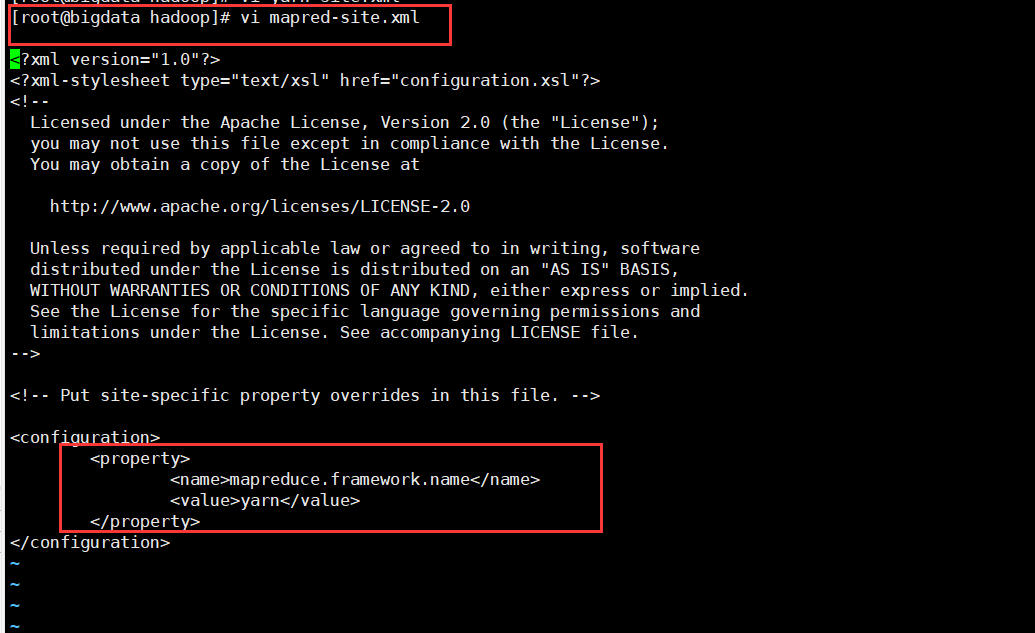
6.配置cp mapred-site.xml.template mapred-site.xml| cp mapred-site.xml.template mapred-site.xml |

7.vi mapred-site.xml <property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> |
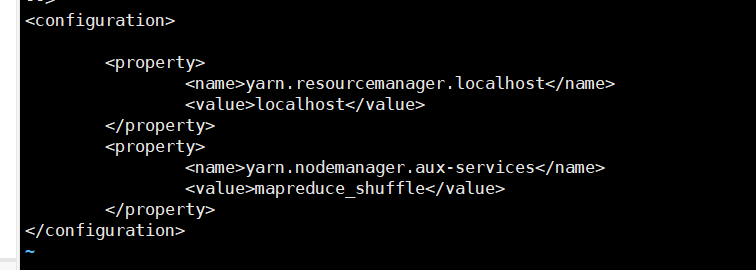
8.vi yarn-site.xml
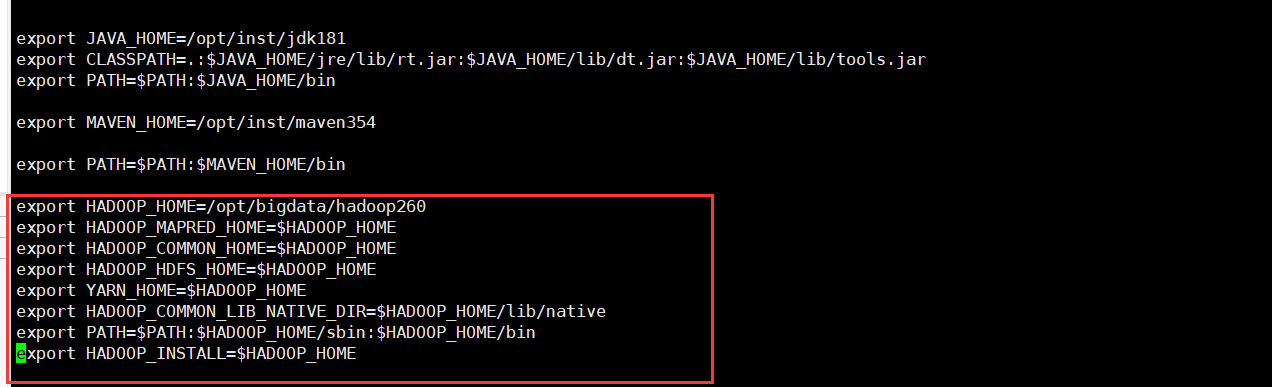
9.vi /etc/profile export HADOOP_HOME=/opt/bigdata/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME |
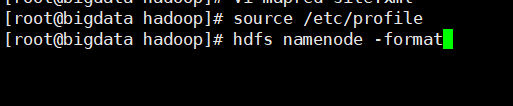
10.更新并格式化 source /etc/profile
hdfs namenode -format |
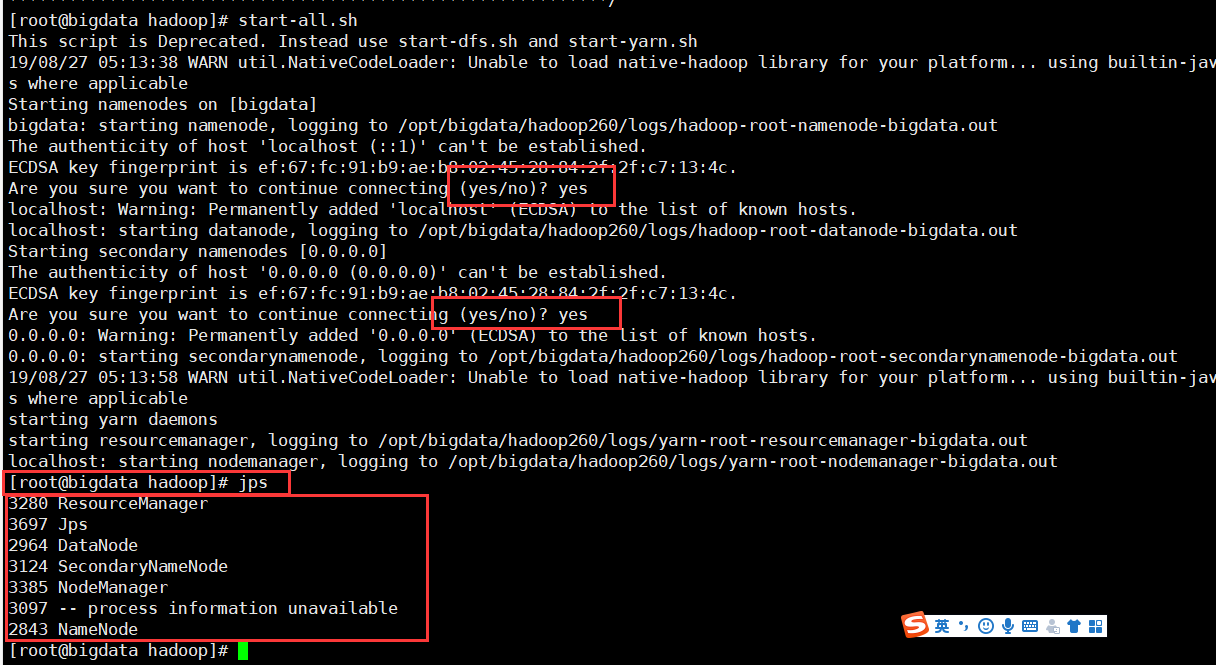
11.启动

12.把linux导入到hadoop中 hdfs dfs -put /opt/a.txt /cm/
hdfs dfs -ls /cm |

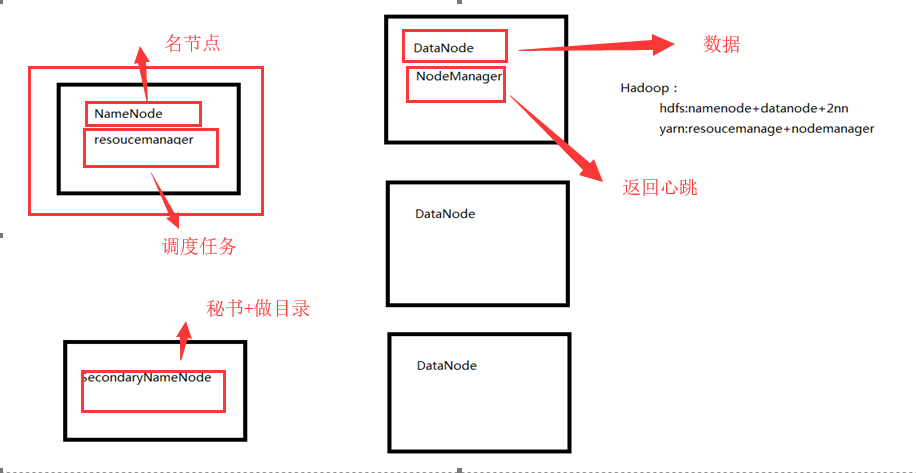
Hadoop理解 三大核心 1.HDFS: Hadoop Distribute File System 分布式文件系统 ? NameNode:主节点,目录
? DataNode:从节点,数据
? SecondaryNameNode:主节点的备份
2.YARN:Yet Another Resource Negotiator 资源管理调度系统 ? 调度的是内存的资源和CPU的算力
? 通过ResourceManager(只有一个) 来调度
? ResourceManager主要作用:
? 1.处理客户端请求
? 2.监控NodeManager
? 3.启动或监控ApplicationMaster()
? 4.资源的分配或调度
? NodeManager(多个)
? NodeManager主要作用:
? 1.管理单个节点上的资源
? 2.处理来自ResourceManager的命令
? 3.处理来自ApplicationMaster的命令
3.MapReduce:分布式运算框架 ? 运算的

----------------------------
原文链接:https://blog.51cto.com/14522074/2434368
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2020-03-13 11:32:19 重新编辑]
|
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 复制
复制 引用
引用




