|
|
Spark的客户端(Driver)有两种:Spark Submit和Spark Shell。这两种客户端相同点都是维护一个Spark Context对象,来向Spark集群提交任务;不同点是Spark Submit只能提交任务,不能交互,而Spark Shell是一个命令行工具,即可以提交任务,还可以人机交互。本节先来介绍Spark Submit客户端的使用。
例子:使用蒙特卡罗方法计算圆周率。
1.蒙特卡罗方法计算圆周率的基本思想 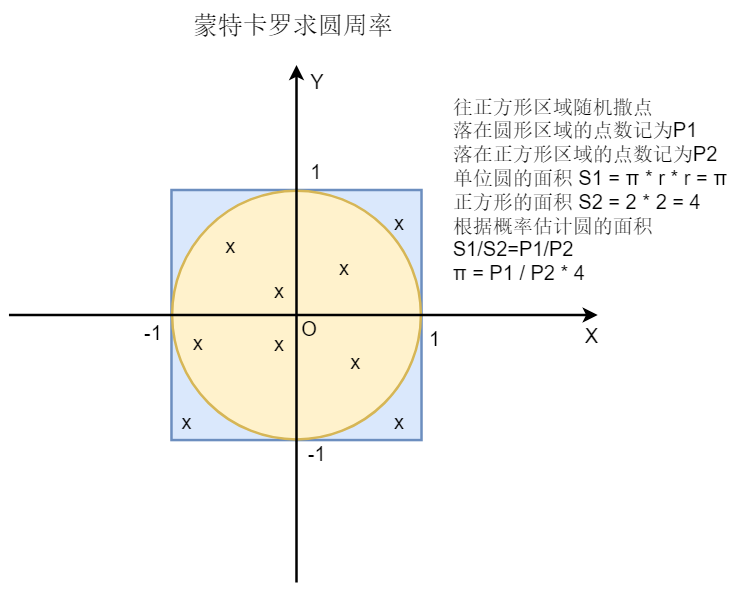
如图所示,蒙特卡罗方法求圆周率,使用的是概率的思想:往正方形区域随机撒点,总点数记为P2,落在单位圆区域内的点数记为P1,单位圆的面积为π,正方形的面子为4,π = P1 / P2 * 4。这里的P1和P2均由随机实验中得到,实验的次数(P2)越多,得到的结果就越精确。
2.使用Spark Submit提交测试用例SparkPI Spark提供的测试用例$SPARK_HOME/examples/jars/spark-examples_2.11-2.1.0.jar中就有蒙特卡罗求圆周率的例子SparkPI,我们就使用它来介绍Spark Submit的使用。
2.1启动Spark集群 (1)如果配置了基于Zookeeper的Spark HA,需要先启动Zookeeper服务器
[root@master ~]# zkServer.sh start
(2)启动Spark集群
[root@master ~]# start-all.sh
[root@master ~]# jps
3578 Jps
3468 QuorumPeerMain
3501 Master
[root@slave1 ~]# jps
1992 Worker
2073 Jps
[root@slave2 ~]# jps
2082 Jps
1992 Worker
2.2使用Spark Submit提交SparkPI任务 使用Spark Submit的命令格式如下:
spark-submit --master SparkMaster节点 --class Java类名 Jar包 其他参数
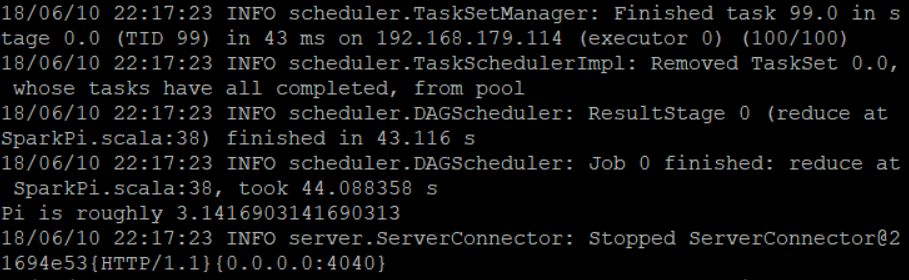
(1)提交SparkPI任务,随机实验次数为100:
[root@master ~]# cd /root/training/spark-2.1.0-bin-hadoop2.7/
[root@master spark-2.1.0-bin-hadoop2.7]# bin/spark-submit --master spark://master:7077
--class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 100
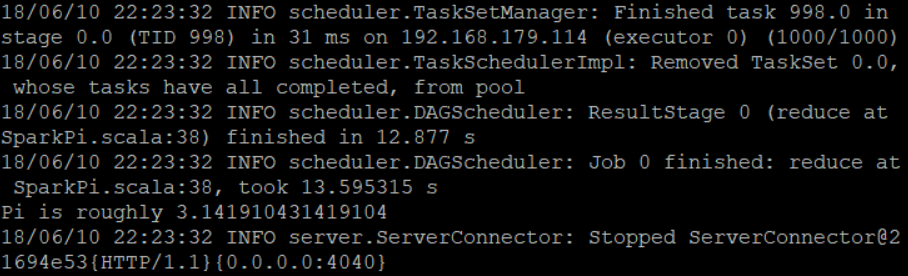
(2)提交SparkPI任务,随机实验次数为1000:
[root@master spark-2.1.0-bin-hadoop2.7]# bin/spark-submit –master spark://master:7077
–class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 1000
(3)提交SparkPI任务,随机实验次数为10000:
[root@master spark-2.1.0-bin-hadoop2.7]# bin/spark-submit –master spark://master:7077
–class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 10000
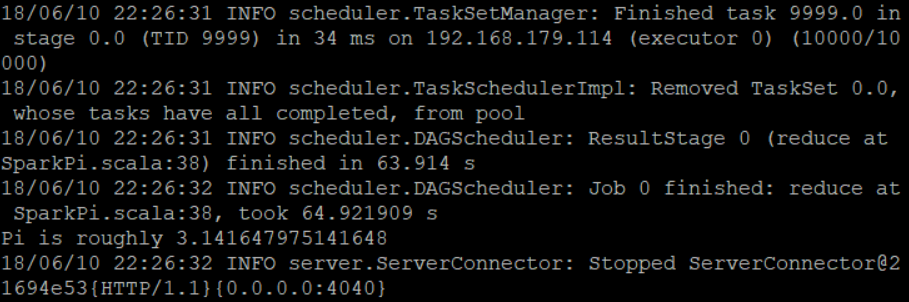
可以看到上面三次实验的结果分别是:
PI = 3.1416903141690313
PI = 3.141910431419104
PI = 3.141647975141648
一般对于随机实验来说,试验次数越多结果越精确。但是不免存在误差。如果想要获取更精确的圆周率,你可以输入更多的次数进行测试。但这不是本文介绍的重点。
至此,使用Spark Submit客户端提交Spark任务的方法已经介绍完毕,祝你玩的愉快!
----------------------------
原文链接:https://www.jianshu.com/p/fec4d0dcb164
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2020-06-18 10:55:29 重新编辑]
|
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用




