|
|
1. 集群环境
Master 192.168.2.100
Slave1 192.168.2.101
Slave2 192.168.2.102
2. 下载安装包
#Master
wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.8.4/hadoop-2.8.4.tar.gz
tar zxvf hadoop-2.8.4.tar.gz
3. 修改Hadoop配置文件
#Master
cd hadoop-2.8.4/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
vim yarn-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
vim slaves
slave1
slave2
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.8.4/tmp</value>
</property>
</configuration> |
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.8.4/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.8.4/dfs/data</value>
</property>
<property>
<name>dfs.repliction</name>
<value>3</value>
</property>
</configuration> |
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> |
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration> |
#创建临时目录和文件目录
mkdir /usr/local/hadoop-2.8.4/tmp
mkdir -p /usr/local/hadoop-2.8.4/dfs/name
mkdir -p /usr/local/hadoop-2.8.4/dfs/data
4. 配置环境变量
#Master、Slave1、Slave2
vim ~/.bashrc
HADOOP_HOME=/usr/local/src/hadoop-2.8.2
export PATH=$PATH:$HADOOP_HOME/bin
#刷新环境变量
source ~/.bashrc
5. 拷贝安装包
#Master
scp -r /usr/local/src/hadoop-2.8.4 root@slave1:/usr/local/src/hadoop-2.8.4
scp -r /usr/local/src/hadoop-2.8.4 root@slave2:/usr/local/src/hadoop-2.8.4
6. 启动集群
#Master
#初始化Namenode
hadoop namenode -format
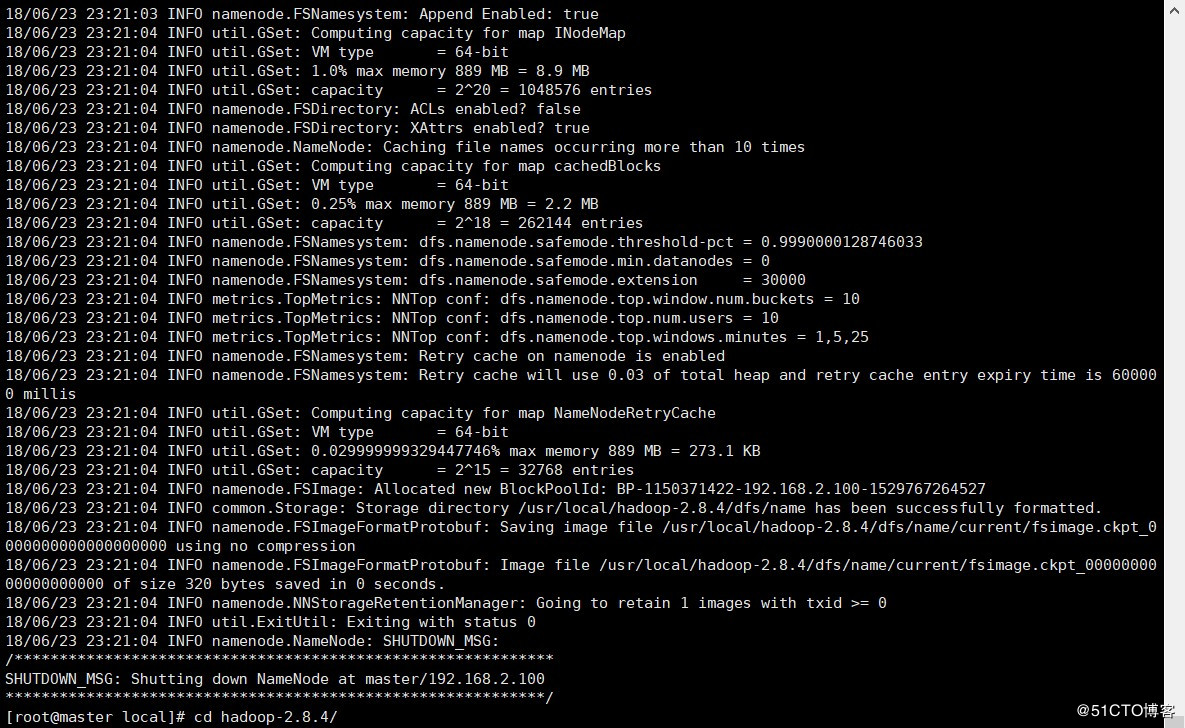
#启动集群
./sbin/start-all.sh
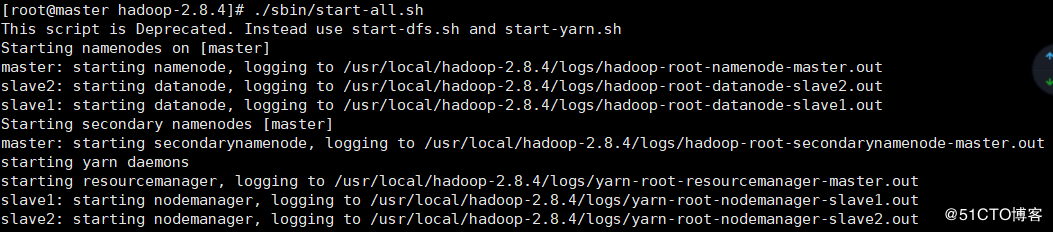
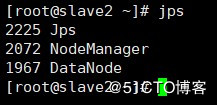
6. 集群状态
jps
#Master
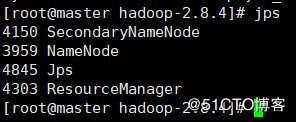
#Slave1
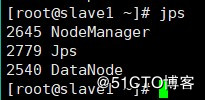
#Slave2
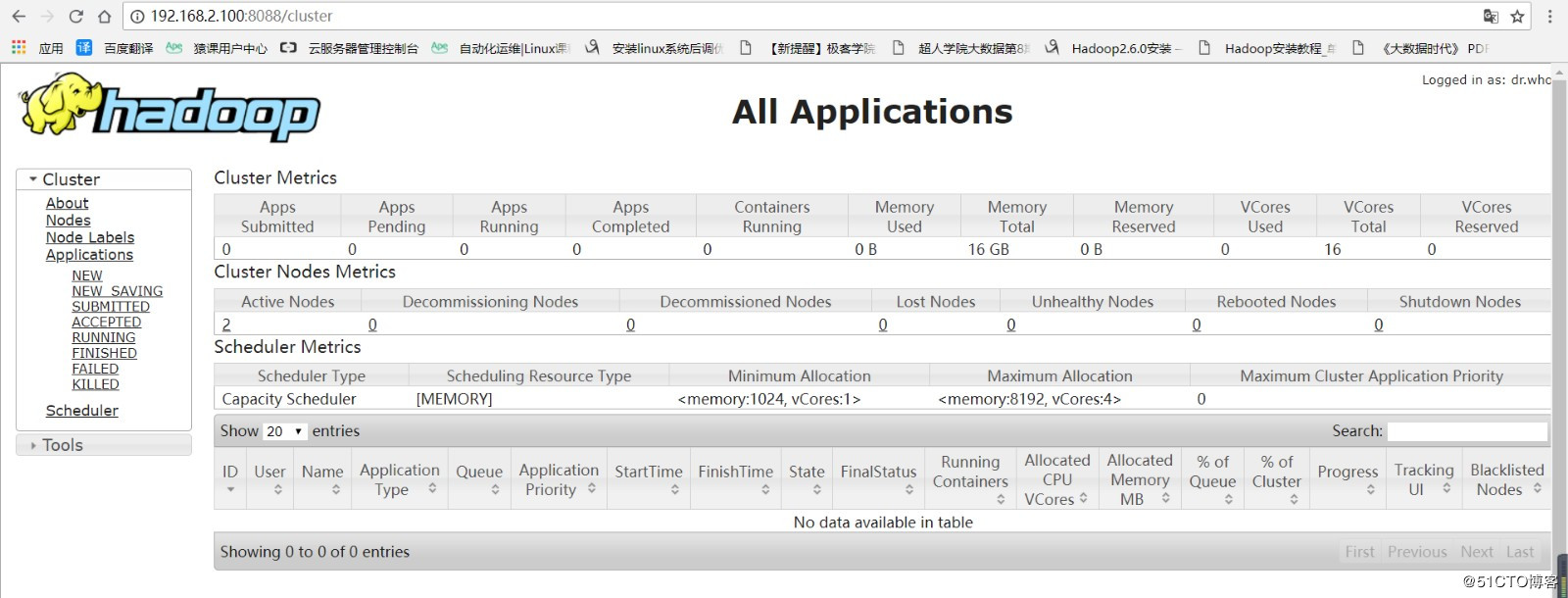
7.监控网页
http://master:8088
- 测试

- 关闭集群
./sbin/hadoop stop-all.sh
----------------------------
原文链接:https://blog.51cto.com/xtbao/2132130
程序猿的技术大观园:www.javathinker.net
|
|















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用




