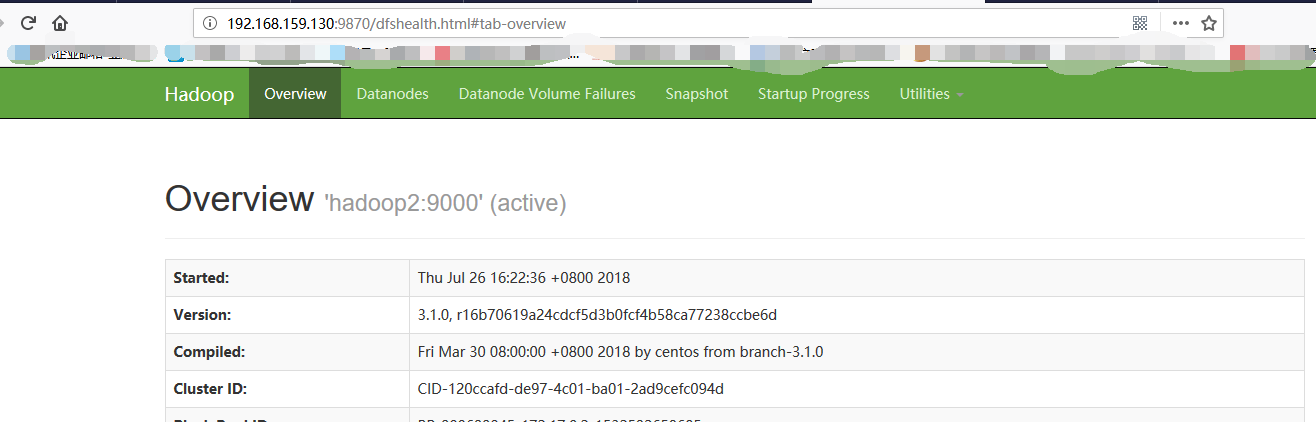
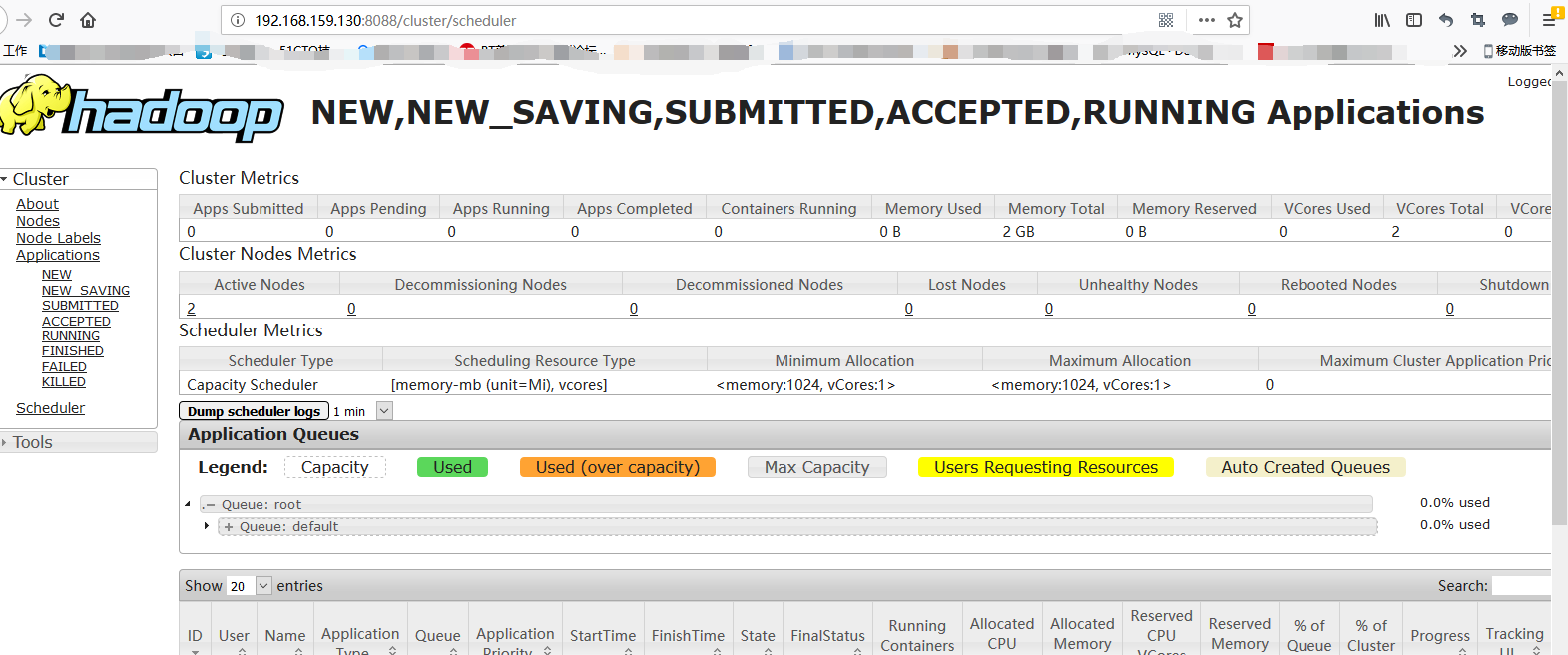
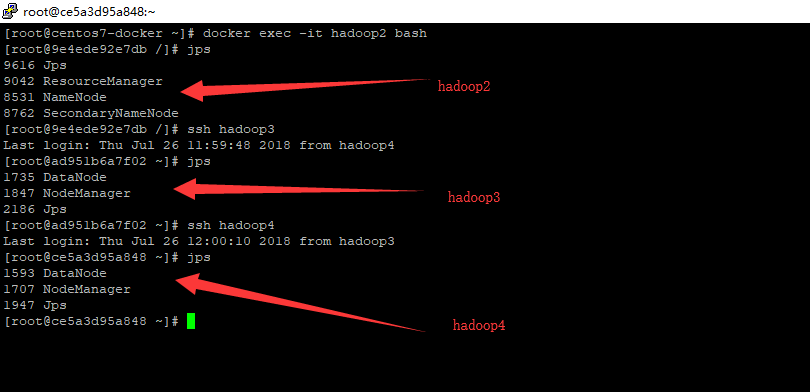
|
 |

|

|

|

|

|

|

|

|

|
| >> 欢迎您 客人: 登录 | 注册 | 在线 | 搜索 | 风格 | 帮助 | 统计 | 文章 | 返回首页 |
|
|||||||||||||
|
| >>分享SPSS,Hadoop等大数据处理技术,以及分布式架构以及集群系统的构建 | 书籍支持 | 卫琴直播 | 品书摘要 | 在线测试 | 资源下载 | 联系我们 |
|
|



|
您是本文章第 31316 个阅读者

|
|
|
||||||||||
|
||||||||||
威望: 0 级别: 侠客 魅力: 经验: 现金: 1176 发文章数: 22 篇 注册时间: 0001-01-01 |
|
|||||||
|
|
|
|
|
|
| 中文版权所有: JavaThinker技术网站 Copyright 2016-2026 沪ICP备16029593号-2 荟萃Java程序员智慧的结晶,分享交流Java前沿技术。 联系我们 如有技术文章涉及侵权,请与本站管理员联系。 |

 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用