def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf()
// .setMaster("local[2]")
.setAppName(s"${_01HiveContextOps.getClass.getSimpleName}")
val sc = new SparkContext(conf)
val hiveContext = new HiveContext(sc)
hiveContext.sql("show databases").show()
hiveContext.sql("use mydb1")
// 创建teacher_info表
val sql1 = "create table teacher_info(
" + "name string,
" + "height double)
" + "row format delimited
" + "fields terminated by ','"
hiveContext.sql(sql1)
// 向表中加载数据
hiveContext.sql("load data inpath 'hdfs://ns1/data/hive/teacher_info.txt' into table teacher_info")
hiveContext.sql("load data inpath 'hdfs://ns1/data/hive/teacher_basic.txt' into table teacher_basic")
// 第二步操作:计算两张表的关联数据
val sql3 = "select
" + "b.name,
" + "b.age,
" + "if(b.married,'已婚','未婚') as married,
" + "b.children,
" + "i.height
" + "from teacher_info i
" + "inner join teacher_basic b on i.name=b.name"
val joinDF:DataFrame = hiveContext.sql(sql3)
val joinRDD = joinDF.rdd
joinRDD.collect().foreach(println)
hive (mydb1)>
>
>
> show tables;
OK
t1
t2
t3_arr
t4_map
t5_struct
t6_emp
t7_external
t8_partition
t8_partition_1
t8_partition_copy
t9
t9_bucket
teacher
teacher_basic
teacher_info
test
tid
Time taken: 0.057 seconds, Fetched: 17 row(s)
hive (mydb1)> select *
> from teacher_info;
OK
zhangsan 175.0
lisi 180.0
wangwu 175.0
zhaoliu 195.0
zhouqi 165.0
weiba 185.0
Time taken: 1.717 seconds, Fetched: 6 row(s)
hive (mydb1)> select *
> from teacher_basic;
OK
zhangsan 23 false 0
lisi 24 false 0
wangwu 25 false 0
zhaoliu 26 true 1
zhouqi 27 true 2
weiba 28 true 3
Time taken: 0.115 seconds, Fetched: 6 row(s)
hive (mydb1)> select *
> from teacher;
OK
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
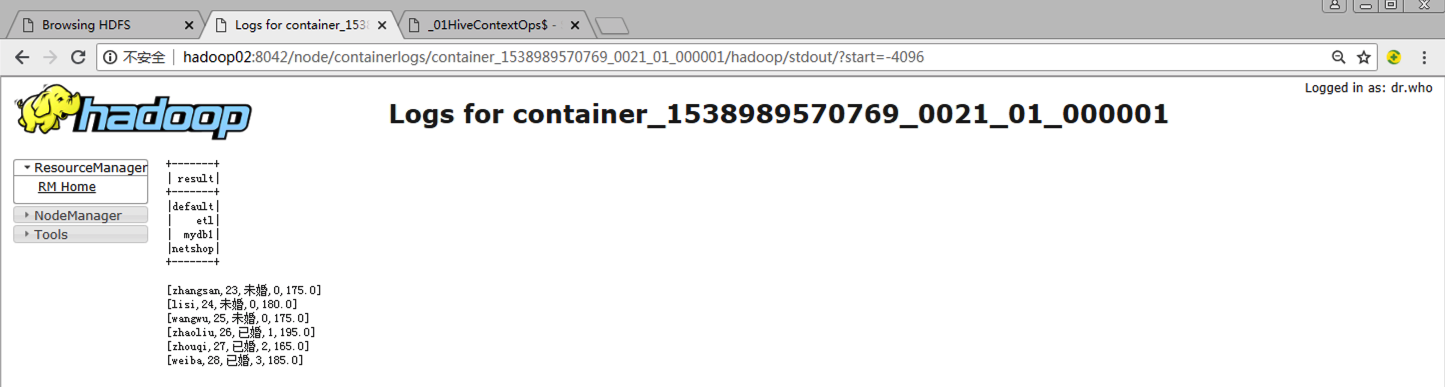
zhangsan 23 未婚 0 175.0
lisi 24 未婚 0 180.0
wangwu 25 未婚 0 175.0
zhaoliu 26 已婚 1 195.0
zhouqi 27 已婚 2 165.0
weiba 28 已婚 3 185.0
Time taken: 0.134 seconds, Fetched: 6 row(s)
5 问题与解决
1.User class threw exception: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
2.User class threw exception: org.apache.spark.sql.execution.QueryExecutionException: FAILED: SemanticException [Error 10072]: Database does not exist: mydb1















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用