|
|
背景 由于历史原因文件数据被存到两套FastDFS环境中,由于项目需求需要将两套环境合为一个,需要提供统一的接口来访问数据,这时就要将两套环境的数据合并到一起了。检查发现两套FastDFS上传生成的Key不同,顾这里不用考虑文件冲突的问题。
简单验证了下,将环境B的storage直接拷贝到环境A,并通过环境A的域名进行访问,是可以做到数据合并(FastDFS通过Nginx访问数据,故只要Nginx指向的路径上存在文件,访问是没问题的)。但是这带来一个问题,后期FastDFS扩容增加节点时,这些拷贝过来的文件由于不被环境A的tracerServer所识别,所以这部分数据在扩容后可能会出现异常。
环境信息- 环境A地址 192.168.1.49 文件key为wKgBMV.....
- 环境B地址 172.18.73.129 文件key为rBJJgV...
- 环境A新增服务器地址 192.168.1.50(用于迁移环境B的数据)
- 环境A的扩展服务器地址 192.168.1.51(用于合并后验证集群扩展)
实现原理 FastDFS4.0后新增storage_id功能,可以为每个storage的节点指定id别名。当storage迁移时,若迁移后的IP与原服务IP不一致时,只需修改ID的指向即可完成迁移。此次由于两套环境都未开启storage_id,故只需在两套环境分别开启,并为其分配不同的id(id不能不冲突)。然后在环境A上新增一个节点,新节点使用的ID是环境B已经指定的id,再将环境B的数据放到这个新增节点上,这样两个节点之间会自动相互同步数据,实现合并。
若已经开启storage_id,且id冲突,这里猜想只需扩容一次,分配到一个新ID,将新ID的数据迁移过去再合并即可。
操作过程 一、开启storage_id 1. 修改/etc/fdfs/tracker.conf
#use_storage_id = false
use_storage_id = true
将100001的ID分配给环境A(192.168.1.49),将100002的ID分配给环境B(172.18.73.129)
2. 修改环境A /etc/fdfs/storage_ids.conf
[root@localhost fdfs]# cat /etc/fdfs/storage_ids.conf
# <id> <group_name> <ip_or_hostname>
100001 group1 192.168.1.49
# 100002 group1 192.168.0.116
3.修改环境B /etc/fdfs/storage_ids.conf
[root@localhost fdfs]# cat storage_ids.conf
# <id> <group_name> <ip_or_hostname>
# 100001 group1 192.168.0.196
100002 group1 172.18.73.129 |
重启服务,检查切换情况 
二、输出两套环境文件的MD5信息,用于校验。 #生成环境A的文件摘要
[root@localhost ~]# find /data/fastdfs/storage/data/ -type f -print0 | xargs -0 md5sum > /tmp/1.49.md5
#生成环境B的文件摘要
[root@localhost ~]# find /data/fastdfs/storage/data/ -type f -print0 | xargs -0 md5sum > /tmp/73.129.md5 |
三、分别打包两套环境的Storage。 #备份环境A数据,当合并失败时可用于回滚
[root@localhost data]# cd /data/
[root@localhost data]# tar -czf fastdfs-1.49.bak.tar.gz fastdfs/
#备份环境B数据,用于迁移合并
[root@localhost data]# cd /data/
[root@localhost data]# tar -czf fastdfs-73.129.bak.tar.gz fastdfs/ |
四、迁移合并 #修改192.168.1.49 /etc/fdfs/storage_ids.conf,增加10002的信息(此前10002已经预配置为环境B)
[root@localhost data]# cat /etc/fdfs/storage_ids.conf
# <id> <group_name> <ip_or_hostname>
100001 group1 192.168.1.49
100002 group1 192.168.1.50
#在192.168.1.50安装FastDFS,修改/etc/fdfs/storage.conf中的服务器信息(与49使用同一tracker,先不启动)
bind_addr=192.168.1.50
tracker_server=192.168.1.49:22122
#重启1.49的tracker服务
[root@localhost data]# ps -ef|grep trac
root 1938 1 0 10:55 ? 00:00:00 /usr/local/FastDFS/bin/fdfs_trackerd /etc/fdfs/tracker.conf
root 2079 2014 0 11:49 pts/2 00:00:00 grep trac
[root@localhost data]# kill 1938
[root@localhost data]# /usr/local/FastDFS/bin/fdfs_trackerd /etc/fdfs/tracker.conf
#将172.18.73.129的数据拷贝到1.50的storage上
#启动1.50的storage服务
[root@localhost etc]# /usr/local/FastDFS/bin/fdfs_storaged /etc/fdfs/storage.conf |
五、分别检查1.49/1.50的binlog状态。 可以看到两个节点相互同步的日志,最终两个节点状态为ACTIVE为同步完成。 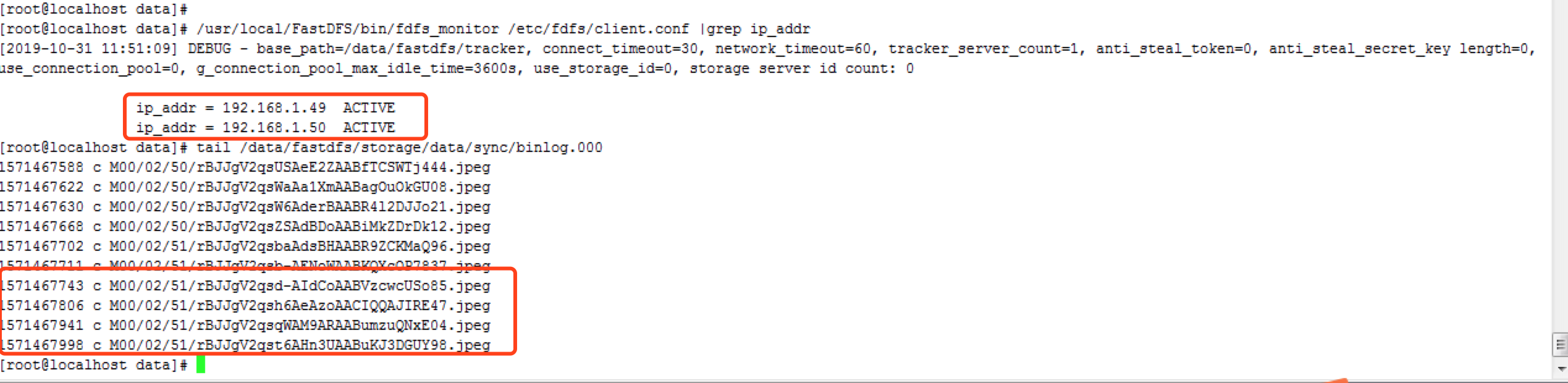
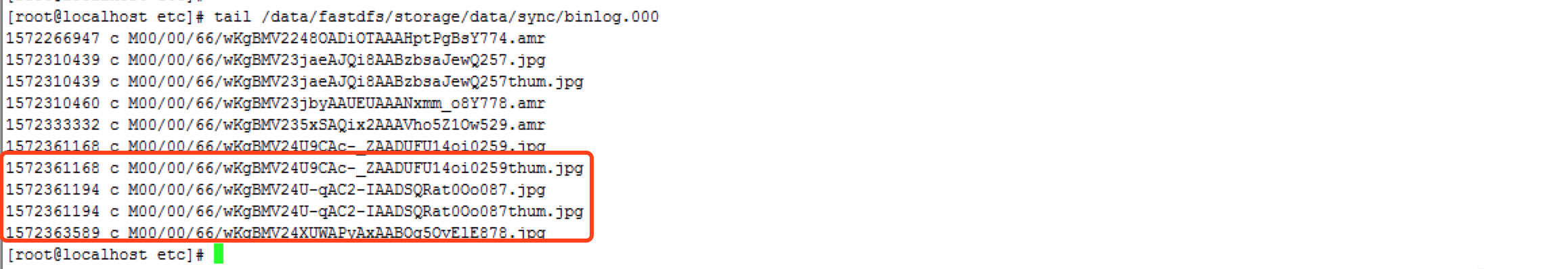
六、用步骤二中生成的md5同时检验两个节点上所有的数据。 在1.49上检验两个md5文件 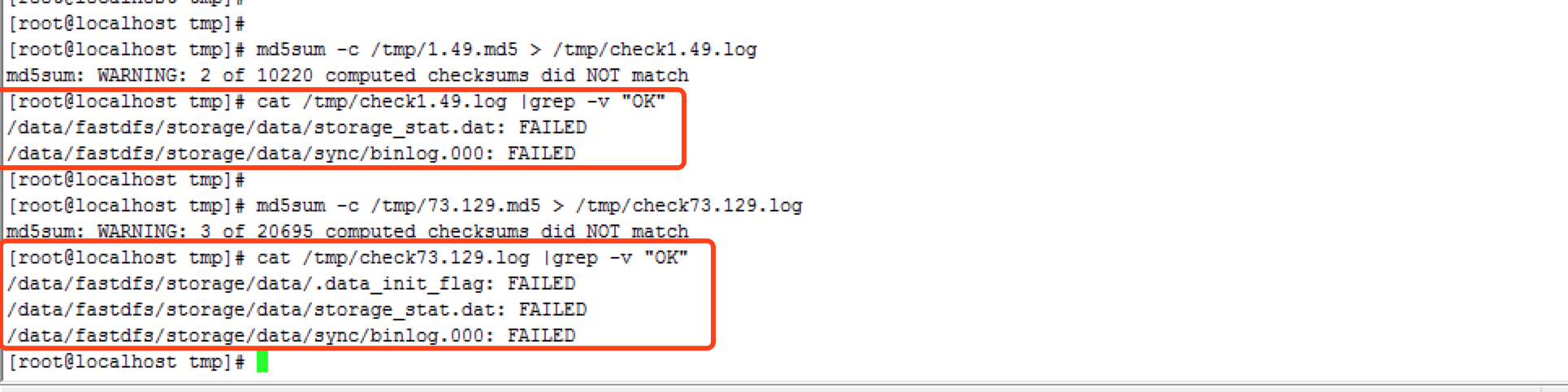
在1.50上检验两个md5文件 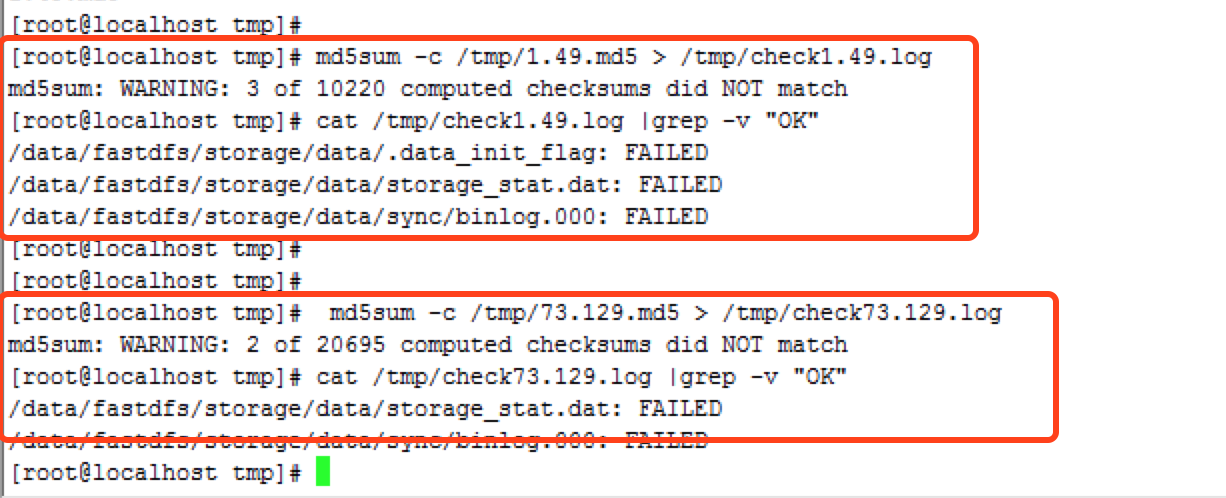
可以看到只有dat和binlog文件的MD5校验不通过,由于合并时这两个文件会被修改,所有这里不用担心。另外没有出现文件丢失的情况。
七、访问数据验证。 通过环境A的url访问原环境B的数据,可以正常读取到。 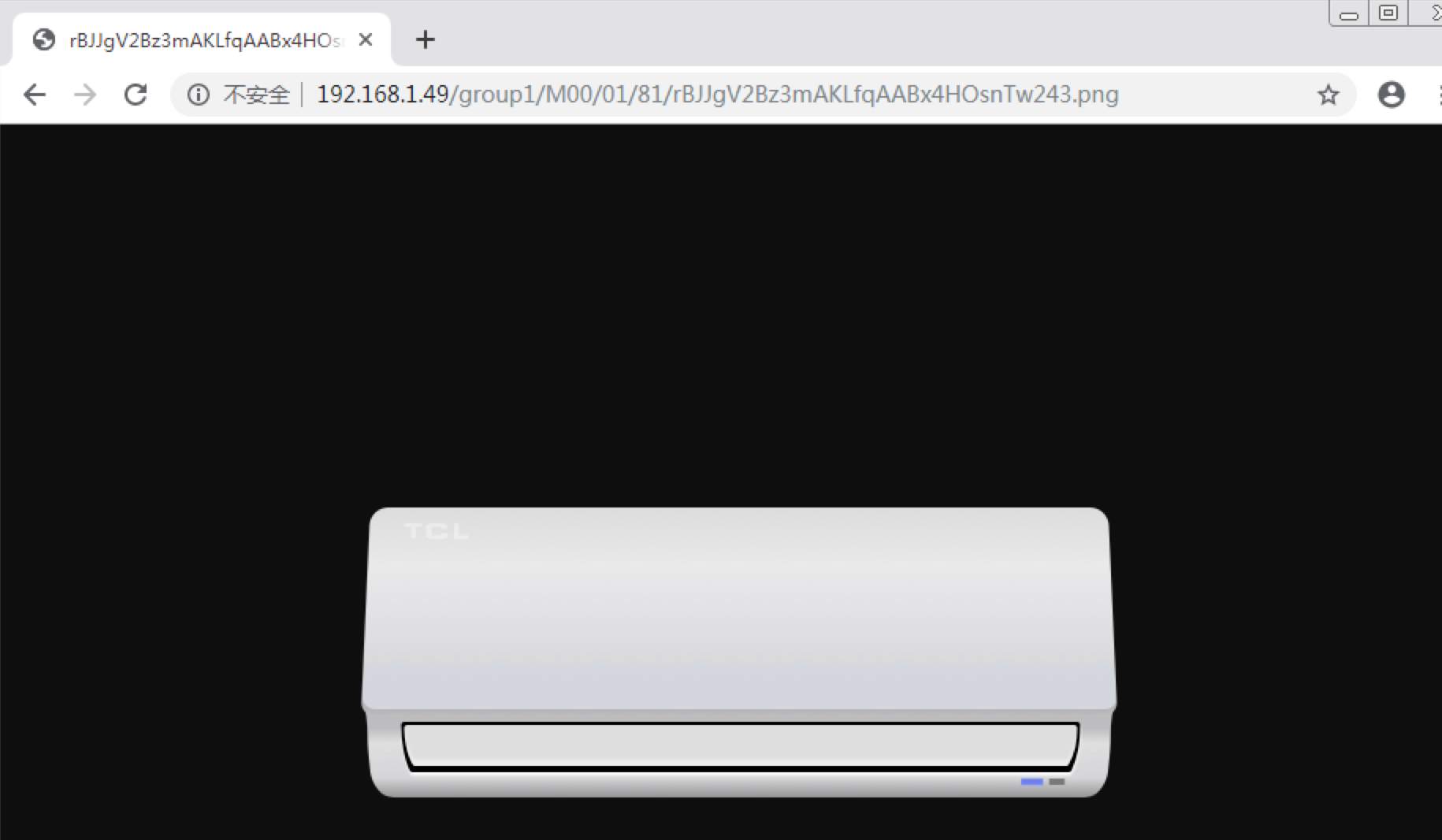
到此,合并已经完成。 八、扩展节点,验证新节点上的所有数据。 前面已经完成了两个环境的数据合并,从校验结果上可以看出所有用户文件都已经正常同步,此处可以测试另加一个storage节点进一步论证合并成功的结论。若合并后的数据能完整的同步到新增节点上,说明合并的信息完整的记录到FastDFS中,确保合并是成功的。
新增一台storage节点,假定IP:192.168.1.51,指定ID为100003。
#修改192.168.1.49 /etc/fdfs/storage_ids.conf,增加10002的信息(此前10002已经预配置为环境B)
[root@localhost data]# cat /etc/fdfs/storage_ids.conf
# <id> <group_name> <ip_or_hostname>
100001 group1 192.168.1.49
100002 group1 192.168.1.50
100003 group1 192.168.1.51
#在192.168.1.51安装FastDFS,修改/etc/fdfs/storage.conf中的服务器信息
bind_addr=192.168.1.51
tracker_server=192.168.1.49:22122
#重启1.49的tracker服务
[root@localhost ~]# ps -ef|grep trac
root 2082 1 0 11:49 ? 00:00:00 /usr/local/FastDFS/bin/fdfs_trackerd /etc/fdfs/tracker.conf
root 2178 2014 0 12:14 pts/2 00:00:00 grep tra
[root@localhost ~]# kill 2082
[root@localhost ~]# /usr/local/FastDFS/bin/fdfs_trackerd /etc/fdfs/tracker.conf
#启动1.51的storage服务
[root@localhost etc]# /usr/local/FastDFS/bin/fdfs_storaged /etc/fdfs/storage.conf |
在1.49上检查storage信息 
在1.51上校验MD5摘要信息。此时可以看到新扩容的节点能同步两套环境的所有文件 
在1.49上传一个文件,然后再3个节点上检查文件是否可以同步。可以看到新上传的文件可以同步到所有数据节点上。 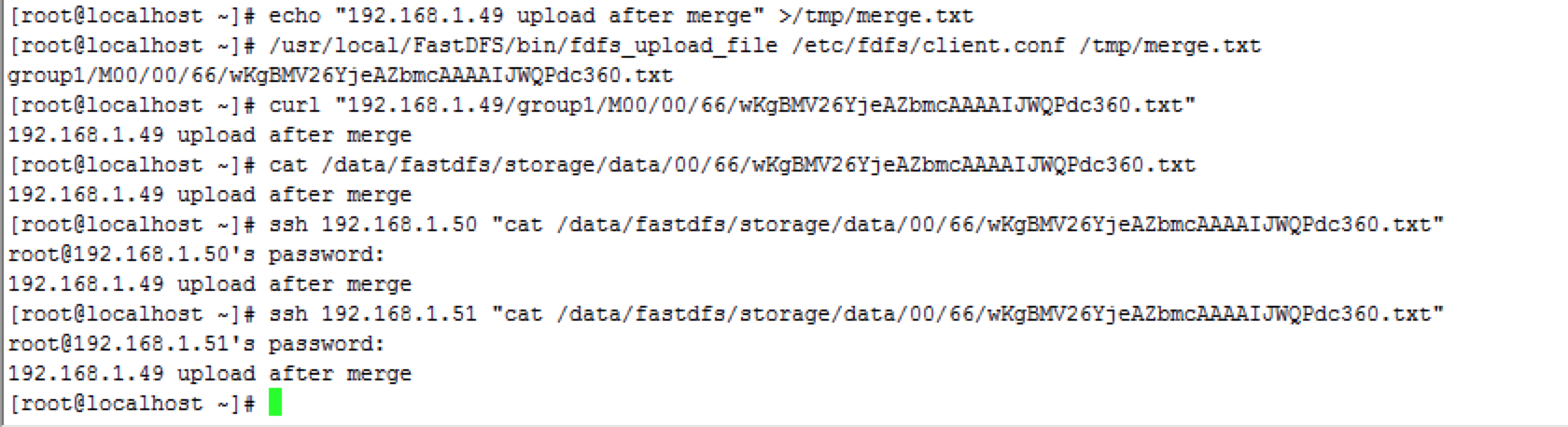
----------------------------
原文链接:https://blog.51cto.com/cubix/2476300
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2020-03-15 10:59:29 重新编辑]
|
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用




