|
|
在分布式存储中面临的一个重要问题是如何在多个存储节点上分布数据。了解 GFS 之类文件系统的同学都知道可以采用元数据服务器( MS )的方式决定数据块在存储节点上的分布映射。采用元数据服务器方式可以很好的将数据和元数据分离,访问文件系统命令空间的时候,可以直接从元数据服务器上获取文件的映射信息。基于 MS 的分布式存储架构如下图所示:
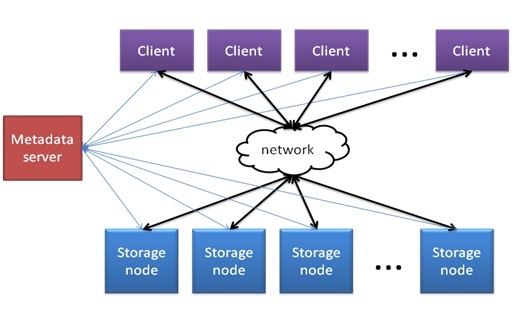
基于元数据服务器的方式是分布式存储的经典架构,虽然看起来很完美,但是还是存在如下两大主要问题:
1, 可扩展性受限于元数据服务器的能力。所有的元数据信息都集中在元数据服务器上面,所以,当 Client 想要获取元数据时就需要访问该服务器。因此,整体的带载能力( Client 的个数)就受限于元数据服务器的能力。元数据服务器就是整个分布式系统的潜在瓶颈点。特别当 Client 访问小文件时,会产生大量的元数据信息,此时元数据服务器就会成为系统性能瓶颈。
2, 元数据服务器是分布式系统中的单点故障点。一旦元数据服务器发生故障,整个分布式存储系统将无法正常工作,因此,元数据服务器的可靠性尤为重要。
总结起来,基于元数据服务器的分布式存储架构最大的问题在于可扩展能力和可靠性。而且这些问题的核心点都在于元数据服务器上。对此也有很多的系统优化手段,例如,针对元数据服务器影响系统可扩展性能力的问题,可以采用分布式元数据服务器的手段进行缓解,但是,又会额外引入分布式元数据服务器之间数据同步和加锁互斥的问题。针对元数据服务器单点故障的问题,可以采用 HA 的手段增强系统可靠性,很多厂商在 Hadoop 分布式文件系统中做了很多元数据服务器 HA 的尝试。
但无论怎么优化,采用元数据服务器方式的分布式存储都不能达到线性可扩展的目的。基本上扩展能力呈现对数 LOG 的曲线方式。为了达到线性可扩展的能力,业界开始考虑如何去掉元数据服务器,即去中心化。其中发展出来的算法有 HASH 算法、一致性 HASH 算法、弹性 HASH 算法和 CRUSH 算法。此处重点讨论一致性 HASH 算法。
在谈到一致性 HASH 的时候,首先需要考虑 HASH 算法。在分布式存储中应用的 HASH 算法很简单,其可以描述如下:
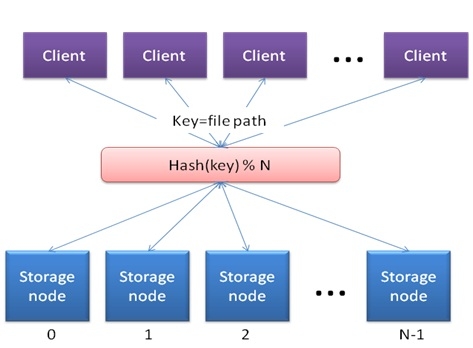
当 Client 需要将一个文件写入 Storage 的时候,可以将文件路径作为 Key 值算出一个 HASH 值,这个 HASH 算法需要有很好的分布特征。在得出这个 HASH 值之后,再和 Storage Node 的个数 N 做取余操作,得出的结果在 0 到 N-1 之间,该结果就是需要访问的 Storage Node 编号。从这种方法来看,一个文件在 Storage Node 中的布局不需要元数据服务器的介入,文件和存储节点之间的映射关系由 HASH 函数来决定,并且是可计算的。
HASH 算法看起来非常的完美,但是,其问题在于如果动态增加一个节点之后,这种数据映射关系就会遭到破坏,原因在于 HASH 算法中的 N 发生了变化。为了建立新的映射关系,不得不需要引入大量的数据迁移操作,这在大规模分布式存储中是不允许发生的。为了解决这个问题,引入了一致性 HASH 算法。
一致性 HASH 的核心思想是将 HASH 结果域做成一个空间,并且为所有的存储节点分配一个标签值,这些标签值属于这个 HASH 值空间。通常这种关系可以描述成一个哈希环,这个空间就构成了这个 HASH 环, 所有存储节点是这个环上的一个点。可以描述如下:
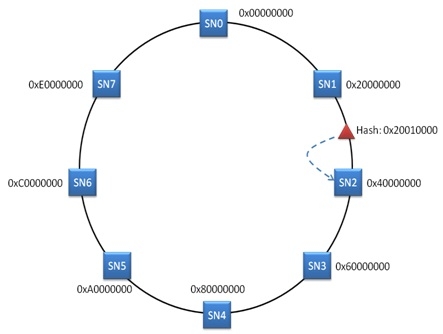
当 Client 需要将一个文件写入 Storage 的时候,同样可以将文件路径作为 HASH 函数的参数,然后得到一个 HASH 值。这个得到的 HASH 值肯定会属于 HASH 值空间,也就是说在 HASH 环上面肯定可以找到一个对应的点。例如,这个点位于 SN1 和 SN2 之间。按照协议,可以选择顺时针离 HASH 值最近的节点作为数据存储点。即新写入的文件可以存入 SN2 。
一致性 HASH 算法的最大优点在于避免添加存储节点之后的大规模数据迁移。例如在刚才的例子中,如果后来在 SN1 和 SN2 之间添加了一个 SN8 ,那么原先存入 SN2 中的一部分数据需要迁移到 SN8 ,但是,其余节点不需要做任何的数据迁移操作。
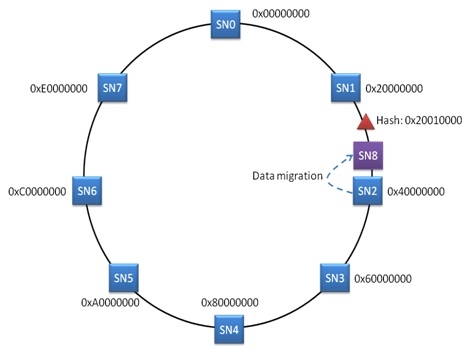
显然这种方法大大降低了数据迁移量,又能很好的避免元数据服务器带来的问题。因此,一致性 HASH 算法被广泛应用到了 CDN 系统、 SWIFT 对象存储系统、 Amazon 的 dynamo 存储系统中。
----------------------------
原文链接:https://blog.51cto.com/alanwu/1431397
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2020-03-19 10:45:55 重新编辑]
|
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用




