|
|
kafka+spark-streaming实时推荐系统性能优化笔记 1) -- conf spark.dynamicAllocation.enabled=false
如果正在使用的是CDH的Spark,修改这个配置为false;开源的Spark版本则默认是false。
当为true时,即使指定了num-executors个数,spark-streaming应用也会占用整个集群的资源。
2) --conf spark.streaming.concurrentJobs=10
这个配置项的默认值为1,代表着新的batch过来之后只能在队列中等待之前的batch执行完之后再执行。
如果batch执行的时间超过了batch本身的时间,可以将该配置增大。
修改该配置的风险:kafka的单个partition只支持顺序消费,如果排在后面的batch先执行完成,kafka consumer 在commit offset时会出现混乱。
建议,使用之前充分评估风险,否则尽量不修改该配置。
3) cache persist 和broadcast的选择
使用spark-streaming的应用一般是实时或者准实时的应用,所以需要预加载的变量(如模型,矩阵等),一般不会选择cache和persist,而是使用广播变量broadcast(只读,类似于全局变量,但是如果在
spark中直接使用全局变量会大幅降低程序性能)。
另一方面,将rdd/df的cache改为map(key,value)形式后进行广播,可以在需要对该rdd/df进行join的地方采用rdd.map{m=>get(m.key)}的形式来代替。减少了join带来的开销。
4)预加载broadcast变量
广播变量是懒加载的,首次在dataDStream.foreachRDD中使用该广播变量会导致第一批数据处理比较慢,广播变量越大延迟也越大。
懒加载在Spark离线任务中是比较好的策略,但是对线上实时推荐来说,延迟10s以上的行为数据可能都已经没有处理价值了。
所以可以在还没有进入到foreachRDD中时,先让广播变量能够预加载到每台服务器,设置kafka读取的offset为latest,这样能够保证spark-streaming总是能够处理到最新的数据。
预加载的方法利用了懒加载的性质,随便新建一个df,按照executor的个数repartition之后,在每个partition中读取广播变量的value中的任意一个值(不存在的也可以),这样就能保证每个executor都能加载到该广播变量。
someDF.repartition(sparkSession.sparkContext.getConf.getInt("spark.executor.instances", 10)).foreachPartition {
p =>
bcVariables.value.get("_")
}
5)去掉所有不必要的join
join确实有很多可以优化的配置,但是没必要把时间花在join的优化上,尤其是在可以用广播变量来作为代替方案的情况下。
需要注意的是,广播变量和broadcast join是不一样的,前者效率在大部分时候要更高。
6)kafka partition个数和executor个数的关系
executor个数要能被partition个数整除。例如,如果partition个数为24个,那么12个executor和18个executor处理数据的性能差距不大。如果集群可以分配的executor个数为18个,那么partition数可
以从24个调整为18个(或者36个等等)。
原因比较明显,就不多提了。展示几个实验数据
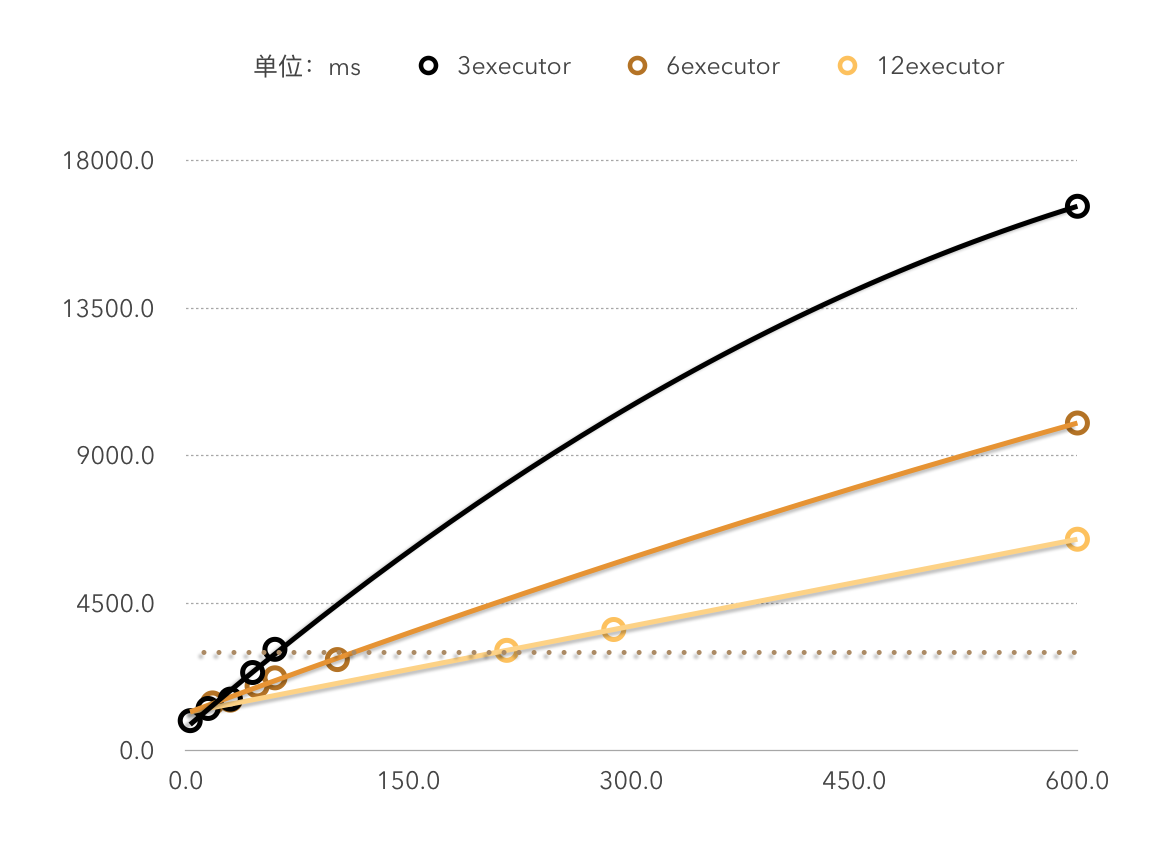
下图为性能测试实验中3,6,12个executor下数据处理时间(纵坐标)和数据量(横坐标)的关系,是明显的线性关系。
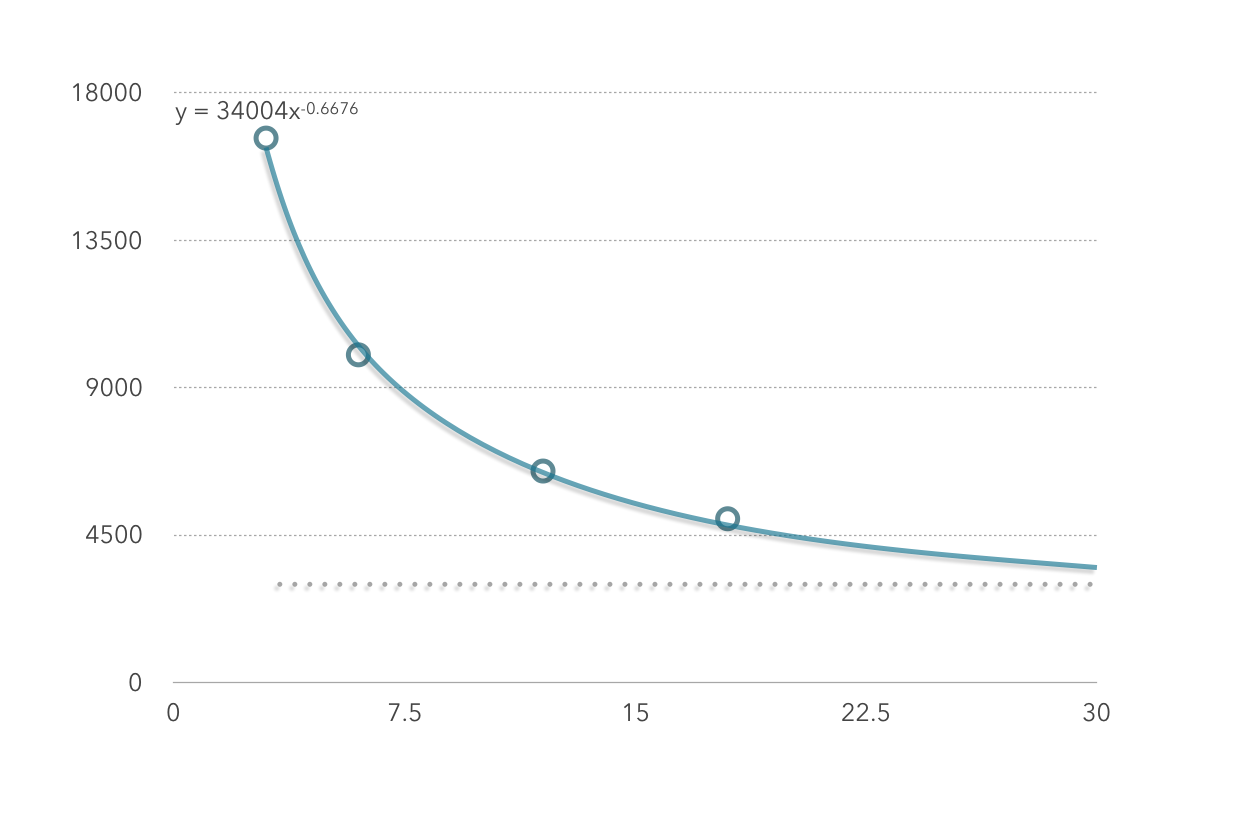
下图为性能测试实验中在处理600条数据时,executor数(横坐标)和时间(纵坐标)的关系(分区个数为executor的整数倍)
由图一的三组数据也可以看出,每秒能处理的数据的条数和executor的个数约等于线性关系。即如果当前集群每3秒能处理x条数据,那么集群扩容一倍后,每3秒应该能处理2x条数据。
由图二可看出,executor数和数据的处理时间不是简单的线性关系,也就是说,如果当前集群处理100条数据耗时6秒,并不能保证将集群扩容一倍后100条数据的处理时间变为3秒。
7)kafka的hash分区
kafka的各个分区处理的数据应该保证尽量按照某一特征(比如用户id)hash分区,这样能够保证某一用户的所有记录都在某一个partition,这样spark-streaming在处理reduceByKey时会提升效率。
----------------------------
原文链接:https://blog.csdn.net/arli_xu/article/details/83034581
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2020-03-22 10:25:41 重新编辑]
|
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用


